Наверняка каждый разработчик сталкивался с необходимостью распарсить строку. В этом посте я рассмотрю два основных варианта решения этой задачи – самописный и
Рассмотрим первый вариант. Пусть нам, например, нужно распарсить строку, которая представляет собой набор интовых значений (например это будут id каких-нибудь товаров), разделенных запятой. Тогда наш код будет выглядеть
примерно следующим образом:
- -- наша входная строка с айдишниками
- declare @input_str nvarchar(100) = '13,12,34,56,'
- -- создаем таблицу в которую будем
- -- записывать наши айдишники
- declare @table table (id int)
- -- создаем переменную, хранящую разделитель
- declare @delimeter nvarchar(1) = ','
- -- определяем позицию первого разделителя
- declare @pos int = charindex(@delimeter,@input_str)
- -- создаем переменную для хранения
- -- одного айдишника
- declare @id nvarchar(10)
- while (@pos != 0)
- begin
- -- получаем айдишник
- set @id = SUBSTRING(@input_str, 1, @pos-1)
- -- записываем в таблицу
- insert into @table (id) values(cast(@id as int))
- -- сокращаем исходную строку на
- -- размер полученного айдишника
- -- и разделителя
- set @input_str = SUBSTRING(@input_str, @pos+1, LEN(@input_str))
- -- определяем позицию след. разделителя
- set @pos = CHARINDEX(@delimeter,@input_str)
- end
* This source code was highlighted with Source Code Highlighter.
В результате выполнения скрипта получим след результат:

Какие у этого подхода плюсы? Это простота использования и гибкость в формировании входных данных. Минусы заключаются, в том что необходимо дописывать логику для различного рода проверок как на входящие данные так и на промежуточный результат в процессе парсинга. Например, на входе придет строка типа “вот такая строка с кучей пробелов !” , разделителем у которой является пробел, то придется дописывать логику для удаления лишних пробелов.
Второй подход это использование функции, которую предоставляет SQL Server, sys.dm_fts_parser. Рассмотрим пример:
Запрос:
- select *
- from sys.dm_fts_parser(' "строка, которую нужно как-нибудь распарсить" ', 1049, 0, 0)
* This source code was highlighted with Source Code Highlighter.
Результат:
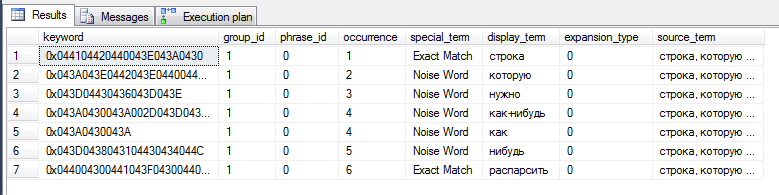
Начнем с запроса – функция примает следующие параметры:
- строку, которую нужно распарсить
- код локали, используемый для анализа входной строки (в примере мы используем локаль для кириллицы)
- список стоп-слов, используемый для разбиения строки на слова, если параметр равен нулю то используется системный список
- последний параметр указывает учитывать или нет диакритические слова (0 – не учитывать, 1 – учитывать)
Теперь посмотрим на результат. Результат представляет собой таблицу состоящую из 8 столбцов. Нас интересуют 4, 5 и 6 столбцы(описание других столбцов можно найти в на msdn). Occurrence (местонахождение) – показывает позицию каждого слова в результате анализа. Spetial_term – указывает на характеристику отдельного слова. Может принимать значения Exact – точное совпадение, Noise Word – слово-шум (например местоимения), а также могут принимать значения: конец строки, абзаца, раздела. И, наконец, столбец display_term(имеет тип nvarchar(4000))– содержит распарсенные слова.
В нашем примере есть два точных совпадения – это слова «строка» и «распарсить». Остальные слова попали в категорию шумов. Также необходимо обратить внимание на слово «как-нибудь». SQL Server разбил его на три составляющие «как-нибудь», «как» и «нибудь», причем первые два варианта идут номер 4, а последний под номером 5.
Интересный результат мы получим на выходе если передадим в качестве строки набор айдишников из первого примера:

SQL Server точно распарсил строку на составляющие числа – в результирующей таблице это нечетные номера строк. Кроме этого появились дополнительные значения в столбце display_term – перед каждым числом стоит специвльное обозначение nn (четные номера строк), т.е. помечая/показывая, что тоже значение (без этой приставки и с тем же номером местоположения) является/может быть целым числом.
Какие плюсы у данного подхода: результат возвращается в виде таблицы, которая содержит такую полезную информацию как местоположение отдельного слова в строке, а также его характеристику; возвращает также возможные альтернативные варианты составных слов (таких как в нашем примере – слово «как-нибудь»); можно выделить/убрать «шум» (Noise word) из результирующего набора. Минусы: необходимо строить дополнительные условия сортировки в результирующей таблице (пример с входящей строкой, содержащей целые числа), нет гибкости в задании четкого разделителя, по которому необходимо парсить строку.
Выводы.
Каждый из рассмотренных подходов имеет свои преимущества и недостатки. Выбор подхода должен осуществляться исходя из поставленной задачи и времени на ее решение.
P.S. Если по какой-то причине ни один из вышеперечисленных способов не подходит то могу предложить еще один способ
Ссылки по теме:
1. sys.dm_fts_parser - http://msdn.microsoft.com/ru-ru/library/cc280463.aspx
2. SQL Server Full-Text Search - http://msdn.microsoft.com/en-us/library/cc721269(v=sql.100).aspx
Спасибо за интересную статью! Очень помогла!
ОтветитьУдалитьХорошая статья, спасибо!
ОтветитьУдалитьset @input_str = SUBSTRING(@input_str, @pos+1, LEN(@input_str)-@pos) ?
ОтветитьУдалитьСпасибо за комментарий! Конечно можно высчитывать подстроку как Вы предложили - передавать точное количество символов, которое нужно взять, однако это абсолютно ничего не изменит, т.к. в моем варианте SQL Server даже при значении последнего параметра (length) функции SUBSTRING большем чем фактически должно быть вернет тоже самое значение что и в вашем варианте.
Удалитьспасибо, помогло
ОтветитьУдалитьХорошая статья, все доходчиво и правильно объяснено. Пишите еще.
ОтветитьУдалить